3345 Henry Road, Anniston, AL 36207 | Phone: (256) 403-1107 | Fax: (866) 963-0139 | Mon-Fri 9:00am - 7:00pm | Sat 9:00am - 6:00pm | Sun 12:00pm - 6:00pm
Get Healthy!
Recent health news and videos.
Staying informed is also a great way to stay healthy. Keep up-to-date with all the latest health news here.
13 Jul
Weight-Loss Drugs Help, But Exercise Is Still the Key to a Healthier Heart
A University of Copenhagen study followed 130 adults after weight loss and found those who exercised had healthier blood vessels and lower inflammation than those relying on weight-loss medication alone.
10 Jul
Hidden Eye Damage After Mild COVID
New research suggests mild COVID can trigger lasting eye problems that standard eye exams may not detect.
09 Jul
Three Million Preventable Deaths a Year: Can Healthcare Do Better?
The Hidden Toll of Preventable Medical Harm. HealthDay speaks with Dr. Mark Ramsey, CEO of the Patient Safety Movement.

What Is An Aortic Dissection? The Condition That Killed Sen. Lindsey Graham
The sudden death of Sen. Lindsey Graham this weekend has drawn attention to a fast-moving and often fatal emergency: aortic dissection, a tear in the body's largest artery.
Graham, a Republican from South Carolina, died Saturday night at age 71. He had appeared healthy, which is part of what makes the condition so dangerous, according to <...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 13, 2026
- |
- Full Page

Weight-Loss Drugs Help, But Exercise Is Still The Key To A Healthier Heart
Weight-loss meds are transforming obesity treatment.
But when it comes to heart health, exercise may still be the game changer.
"The study shows that while medication supports weight maintenance, it is exercise — with or without medication — that improves vascular health," said researcher Signe Torekov, a professor of bio...
- HealthDay Staff HealthDay Reporter
- |
- July 13, 2026
- |
- Full Page

Adderall Misuse Falls Sharply Among Young Adults, Study Finds
Half as many young adults are misusing Adderall, Ritalin and other ADHD medications these days to help them remain alert at study or work, a new evidence review says.
Misuse of ADHD stimulant meds among adults under 30 fell from 7.5% in 2016 to 3.7% in 2023, researchers report in the Journal of Clinical Psychopharmacology.
&...
- Dennis Thompson HealthDay Reporter
- |
- July 13, 2026
- |
- Full Page

Smartphones Can Increase Seniors' Risk Of Depression
Smartphones can contribute to depression among seniors, depending on how they’re using the devices, a new study says.
Older folks who compulsively use their phones to scroll news, watch videos or play games alone are more likely to withdraw from others, increasing their depression risk, researchers report in the journal JMIR Agin...
- Dennis Thompson HealthDay Reporter
- |
- July 13, 2026
- |
- Full Page

Pro Soccer Players Show Signs Of Shrinking Brains
World Cup fever has America in its grip, as the international soccer tournament grinds steadily toward the finals.
But a new study is highlighting a darker side to the sport: the toll that soccer can take on the brains of its professional players.
Middle-aged former pro soccer players appear to suffer more shrinkage in key brain regi...
- Dennis Thompson HealthDay Reporter
- |
- July 13, 2026
- |
- Full Page
Mild COVID Can Lead To Long-Term Hidden Eye Problems
Doctors are shedding new light on a hidden eye condition that can develop after even a mild case of COVID.
Researchers say a growing number of patients are experiencing severe eye pain, light sensitivity, trouble reading and difficulty focusing months — or even years — after infection.
Yet routine eye exams often appear n...
- HealthDay Staff HealthDay Reporter
- |
- July 10, 2026
- |
- Full Page

Seniors Know How Sharp They Are At Any Given Time, Study Finds
Seniors have a pretty good handle on how sharp they are at any given moment, a new study says.
Self-ratings captured by smartwatches closely matched seniors' actual brain performance in real-time everyday settings, researchers reported recently in the journal Neuropsychology.
“We found that people’s moment-to-mom...
- Dennis Thompson HealthDay Reporter
- |
- July 10, 2026
- |
- Full Page

Smartphone App Uses Voice To Predict Asthma, COPD Flare-Ups
Voice changes measured by a smartphone app can send up a red flag for people with asthma or COPD, warning them of an oncoming symptom flare-up, a new study says.
In the future, daily voice checks using such an app might be used to monitor for signs of an asthma or COPD exacerbation, researchers write in a study published recently in ER...
- Dennis Thompson HealthDay Reporter
- |
- July 10, 2026
- |
- Full Page

LGBTQ+ People Less Likely To Be Screened For Some Common Cancers
LGBTQ+ people are less likely to be regularly tested for some common forms of cancer, a new study says.
Gay and bisexual women, as well as transgender individuals, are less likely to receive screening for cervical or breast cancers, researchers reported July 6 in the journal Cancer.
“The current data highlight how sexu...
- Dennis Thompson HealthDay Reporter
- |
- July 10, 2026
- |
- Full Page
AI Can Detect Previously Invisible MS Scars In The Brain
Artificial intelligence (AI) can help doctors find previously invisible brain lesions linked to multiple sclerosis, potentially improving their ability to track disease progression, a new study says.
The gray matter of the brain plays a key role in MS progression, but conventional MRI scans can’t detect disease-driven lesions that fo...
- Dennis Thompson HealthDay Reporter
- |
- July 10, 2026
- |
- Full Page

Use Hits Record High As Medicare Opens Access To Weight-Loss Drugs
The share of U.S. adults taking GLP-1 medications to lose weight has reached a record 11%.
That’s about 40 million people — as many folks who live in California, the nation’s largest state.
A new Medicare program that began July 1 could drive that figure higher still.
Current use of GLP-1s has nearly quadruple...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 9, 2026
- |
- Full Page
Foundation Fights Medical Errors That Claim 200,000 U.S. Lives A Year
Medical error is one of the leading causes of death in the United States, and one organization believes those deaths can be stopped.
The Patient Safety Movement Foundation (PSMF), a nonprofit founded in 2012, has set an ambitious goal: zero preventable patient deaths by 2030.
"What we're asking is not rocket science," Dr. Michael Ram...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 9, 2026
- |
- Full Page
Innovative Hip Replacement Cuts Post-Surgery Risk Of Dislocation By 70%
Hip replacement surgery can dramatically improve the life of a person in chronic pain from a bum hip, but afterward patients must move carefully lest they cause their new hip to pop out of joint.
But a better-designed hip implant can reduce a patient’s risk of hip displacement by 70%, researchers reported recently in The Lancet
- Dennis Thompson HealthDay Reporter
- |
- July 9, 2026
- |
- Full Page

Global Study Finds Kids Worldwide Skipping Fruits And Vegetables
Kids around the world aren’t eating enough fruits and veggies, a major new analysis has found.
Plant-based foods are rich in essential nutrients that support children’s normal development and long-term health, researchers said.
But globally kids aren’t consuming the amount of fruits or vegetables recommended by nutr...
- Dennis Thompson HealthDay Reporter
- |
- July 9, 2026
- |
- Full Page
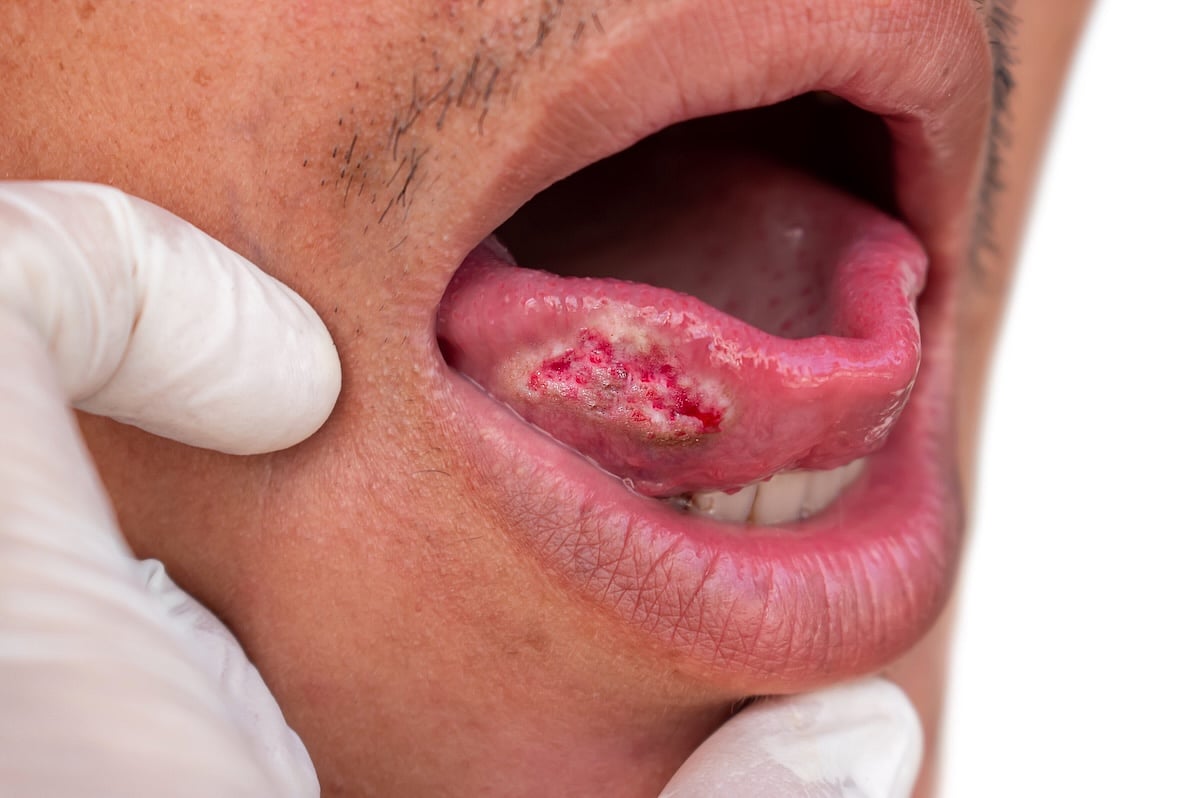
New, Highly Accurate Brush Test Can Detect Mouth Cancer Within An Hour
A non-invasive brush test can diagnose mouth cancer within one hour, potentially boosting detection rates, a new study says.
The brush test proved nearly 96% accurate in detecting oral cancer when tested on hundreds of patients, researchers reported recently in the journal Biomarker Research.
Up to now, diagnosis of oral can...
- Dennis Thompson HealthDay Reporter
- |
- July 9, 2026
- |
- Full Page

E. Coli Outbreak Prompts Recall Of Frozen Blueberries At Publix
An E. coli outbreak linked to frozen blueberries has sickened 12 people, four of them seriously enough to require hospital care, federal health officials say.
The U.S. Centers for Disease Control and Prevention (CDC) and the U.S. Food and Drug Administration (FDA) are investigating a multistate outbreak of illness.
The...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 8, 2026
- |
- Full Page

Drinking Coffee May Lower Your Risk of Liver Disease
The best thing about your morning coffee may not be the caffeine kick.
A study just published in the journal Clinical Gastroenterology and Hepatology suggests as little as one to two cups a day may lower your risk of serious liver disease.
The study included more than 355,000 healthy adults who filled out dietary questionnai...
- HealthDay Staff HealthDay Reporter
- |
- July 8, 2026
- |
- Full Page

U.S. Teens Underestimate Risks Of Fentanyl Use, Survey Finds
U.S. teens are seriously underestimating how lethal the synthetic opioid fentanyl can be, a new study says.
More than half of American eighth-graders don’t think it’s dangerous to experiment with fentanyl, researchers reported July 7 in JAMA Network Open.
In reality, fentanyl is involved in at least 3 out of 4 te...
- Dennis Thompson HealthDay Reporter
- |
- July 8, 2026
- |
- Full Page

Men More Likely To Be Diagnosed With Advanced Cancer
More men die from cancer than women, and a new study suggests one potential reason why.
Men are more likely than women to be diagnosed with advanced cancer that has spread to other parts of the body, researchers report in the July issue of the journal Cancer Epidemiology, Biomarkers & Prevention.
That means their cancer ...
- Dennis Thompson HealthDay Reporter
- |
- July 8, 2026
- |
- Full Page

Rumination Plays Key Role In Caregiver Stress, Study Says
Caring for a loved one with dementia can be incredibly stressful — and a great deal of that stress could be coming from caregivers second-guessing themselves, a new study says.
Caregivers who dwell on difficult problems, negative thoughts or distressing events can find their day-to-day anxieties developing into deeper stress, researc...
- Dennis Thompson HealthDay Reporter
- |
- July 8, 2026
- |
- Full Page
